

11月27日晚,DeepSeek悄悄地在Hugging Face 上开源了一个新模型:DeepSeek-Math-V2。这是一个数学方面的模型,也是目前行业首个达到IMO(国际奥林匹克数学竞赛)金牌水平且开源的模型。
在同步发布的技术论文中,DeepSeek表示,Math-V2的部分性能优于谷歌旗下的Gemini DeepThink,并展示了模型在IMO-ProofBench基准以及近期数学竞赛上的表现。
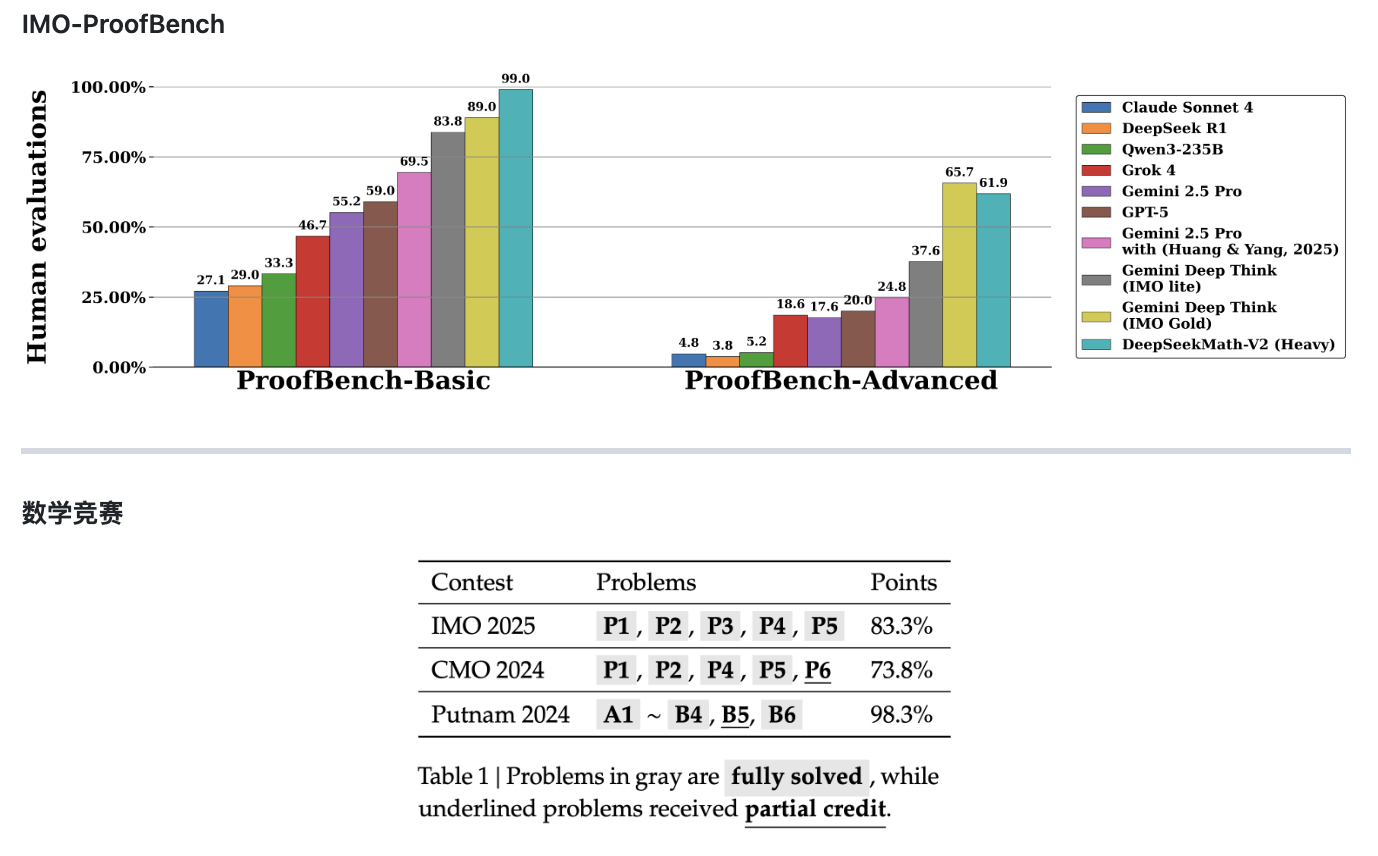
具体来看,在其中的Basic基准上,DeepSeek-Math-V2 远胜其他模型,达到了近99%的高分,而排在第二的谷歌旗下Gemini Deep Think (IMO Gold)分数为89%。但在更难的 Advanced 子集上,Math-V2分数为61.9%,略逊于 Gemini Deep Think (IMO Gold)的65.7%。
在这篇名为《DeepSeek Math-V2:迈向可自验证的数学推理》的论文中,DeepSeek指出,大语言模型已经在数学推理方面取得了重大进展,这是人工智能的重要试验台,如果进一步推进,可能会对科学研究产生影响。

但当前的AI在数学推理方面有着研究局限:以正确的最终答案作为奖励,正确的答案却不能保证正确的推理。许多数学任务,如定理证明,需要严格的分步推导,而不是数字答案,这使得最终答案奖励不适用。
为了突破深度推理的极限,DeepSeek认为有必要验证数学推理的全面性和严谨性。团队提出,自我验证对于扩展测试时间计算尤为重要,特别是对于那些没有已知解决方案的开放问题。
此次DeepSeek推出的Math-V2就从结果导向转向了过程导向,展示了强大的定理证明能力。这一模型不依赖大量的数学题答案数据,而是通过教会AI如何像数学家一样严谨地审查证明过程,从而在没有人类干预的情况下,也能不断提升解决高难度数学证明题的能力 。
论文提到,Math-V2在IMO 2025和CMO 2024上取得了金牌级成绩,在Putnam 2024上通过扩展测试计算实现了接近满分的成绩(118/120)。
DeepSeek认为,虽然仍有许多工作要做,但这些结果表明,可自我验证的数学推理是一个可行的研究方向,可能有助于开发更强大的数学AI系统。
对于DeepSeek此次的动作,海外的反应是“鲸鱼终于回来了”。有网友感慨,DeepSeek以10个百分点的优势击败了谷歌的IMO Gold 获奖模型DeepThink,这不在预测范围内。“想象一下,当他们公布编程模型时会发生什么,我打赌他们绝对有编程模型。”
目前,行业头部厂商的模型已经又迭代了一轮,11月,先是OpenAI发布了GPT-5.1,几天后xAI发布Grok 4.1,就在上周谷歌发布了Gemini 3系列引爆AI圈,“也该轮到DeepSeek出牌了”。不过,更受外界关注的仍然是,DeepSeek的旗舰模型到底什么时候更新,行业期待“鲸鱼”的下一个动作。

1、凡注明来源为“东莞阳光网”的所有文字、图片、音视频、美术设计和程序等作品,版权均属东莞阳光网或相关权利人专属所有或持有所有。未经本网书面授权,不得进行一切形式的下载、转载或建立镜像。否则以侵权论,依法追究相关法律责任。
2、在摘编网上作品时,由于网络的特殊性无法及时确认其作者并与作者取得联系。请本网站所用作品的著作权人直接与本网站联系,商洽处理。
联系邮箱:tougao0769@qq.com
相关阅读


 第十一届东莞台湾名品博览会10月29日举行
第十一届东莞台湾名品博览会10月29日举行



网友跟贴